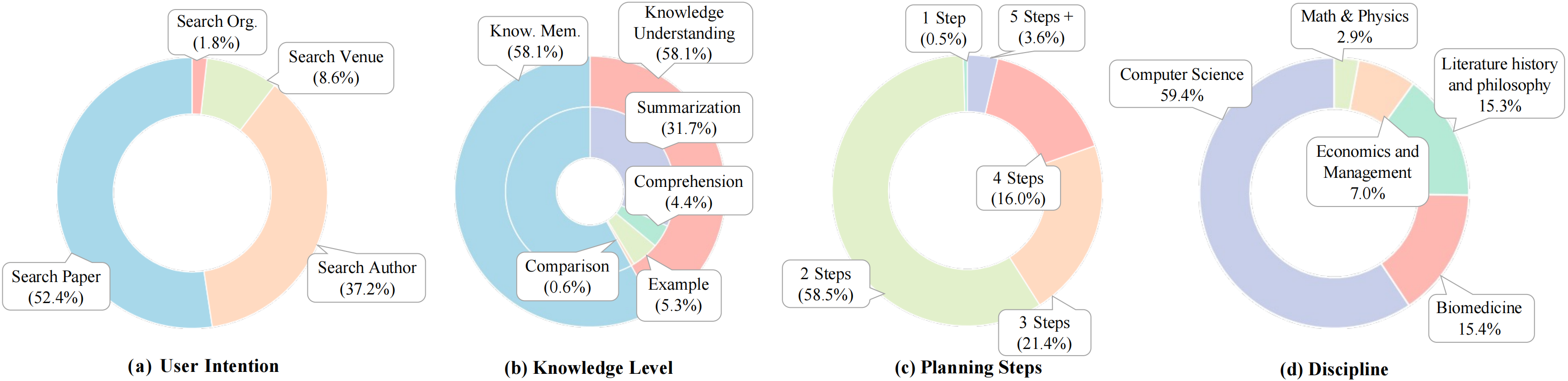
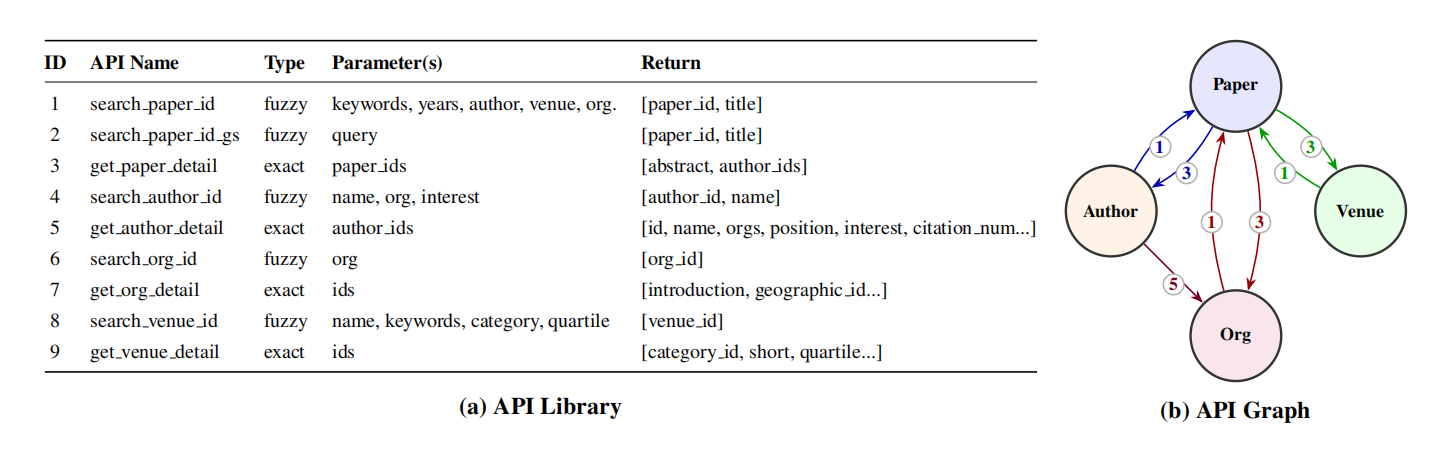
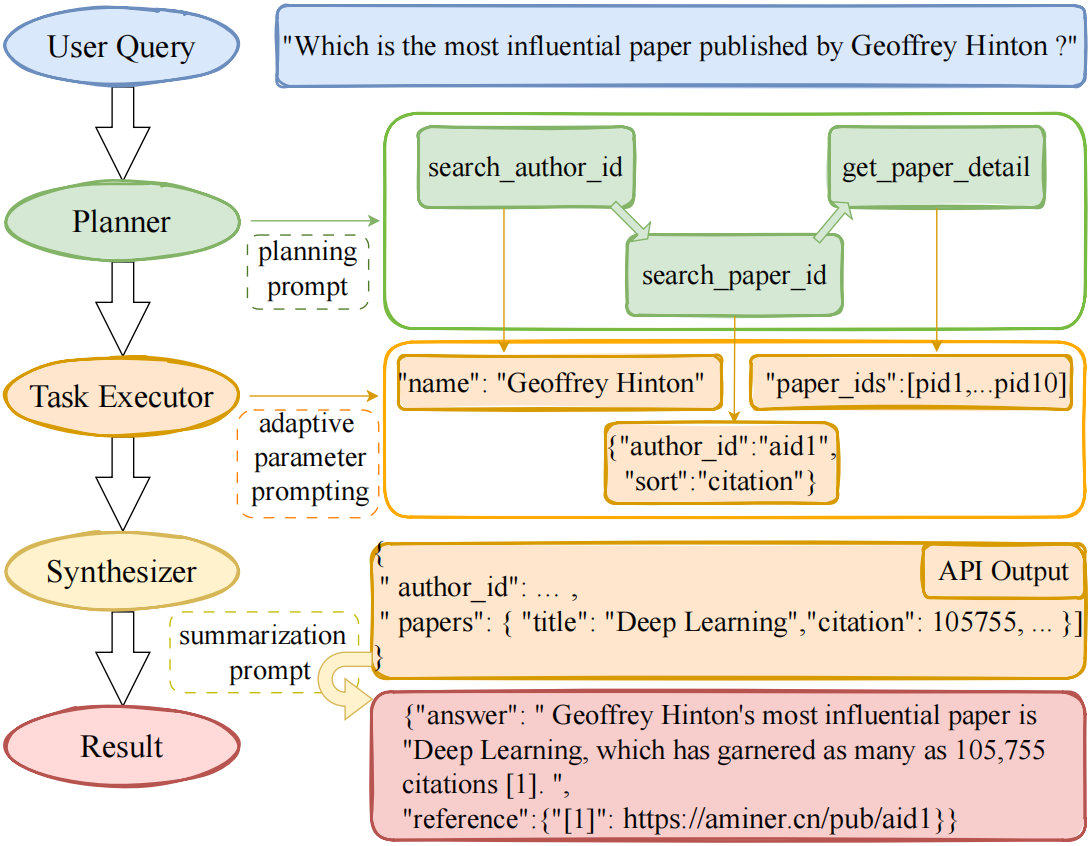
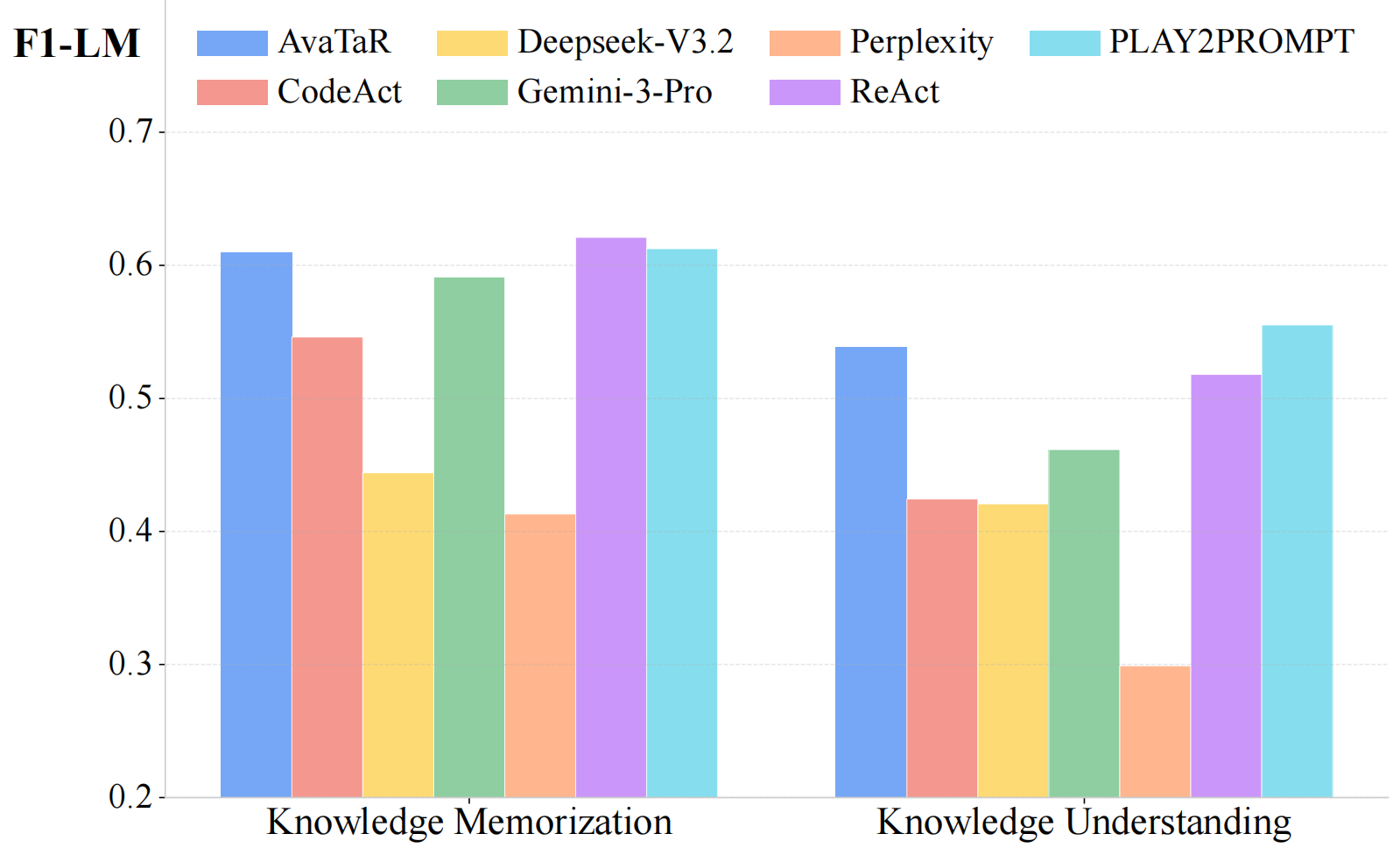
Main evaluation results on the test set.
| # | Model | References and Formatting | API-based Judge | Answer Content | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | Format | Edit Dist. | Para. Acc. | Success | Correct. | Complete. | Faithful. | F1-LM | ||
| CAW | Deepseek-V3.2
DeepSeek-AI |
0.3544 | 0.3461 | 0.78 | 1.56 | 0.4453 | 0.8267 | 0.4571 | 0.4729 | 0.8355 | 0.4649 |
| GLM-4.7
Z.ai |
0.1905 | 0.1659 | 0.4067 | 1.8467 | 0.3474 | 0.8533 | 0.3727 | 0.3510 | 0.6168 | 0.3615 | |
| Qwen3-235B-A22B
Alibaba |
0.4416 | 0.3524 | 0.8467 | 1.84 | 0.4131 | 0.9133 | 0.4936 | 0.4778 | 0.7607 | 0.4856 | |
| GPT-5.2
OpenAI |
0.3008 | 0.3167 | 0.8467 | 5.4667 | 0.3432 | 0.62 | 0.4368 | 0.4562 | 0.787 | 0.4463 | |
| Gemini-3-Pro
|
0.4109 | 0.4342 | 0.74 | 1.2867 | 0.4242 | 0.7867 | 0.5721 | 0.5495 | 0.7907 | 0.5606 | |
| Claude-4.5
Anthropic |
0.1564 | 0.1072 | 0.1467 | 1.7733 | 0.3632 | 0.7733 | 0.3666 | 0.3328 | 0.6705 | 0.3489 | |
| API-Using Agent | ReAct | 0.343 | 0.3779 | 0.7333 | 4.8267 | 0.2705 | 0.9933 | 0.5923 | 0.6015 | 0.7402 | 0.5969 |
| AvaTaR | 0.4313 | 0.4639 | 0.79 | 1.3867 | 0.3522 | 0.9267 | 0.6046 | 0.5894 | 0.826 | 0.5969 | |
| DRAFT | 0.4199 | 0.4545 | 0.7667 | 1.3333 | 0.412 | 0.92 | 0.5873 | 0.5819 | 0.8217 | 0.5846 | |
| PLAY2PROMPT | 0.4308 | 0.4881 | 0.8333 | 1.5267 | 0.3968 | 0.9 | 0.6104 | 0.609 | 0.8542 | 0.610 | |
| Coding Agent | CodeAct | 0.4022 | 0.4313 | 0.8 | 1.3467 | 0.4047 | 0.9467 | 0.5144 | 0.5123 | 0.9295 | 0.5130 |
| SoAy | 0.4275 | 0.4306 | 0.8067 | 1.3067 | 0.3934 | 0.9667 | 0.541 | 0.5008 | 0.7225 | 0.5201 | |
| Deep Research Agent | Perplexity
Perplexity AI |
/ | / | / | / | / | / | 0.3692 | 0.4251 | / | 0.3952 |
| Metaso
Metaso |
/ | / | / | / | / | / | 0.2688 | 0.3025 | / | 0.2847 | |